大型语言模型(LLMs)中的提示缓存:直觉
简要介绍基于注意力的模型中的缓存工作原理

我一直在探索关于提示缓存(Prompt Caching)如何工作的文章,虽然有一些博客提到了它的用处和实现方法,但我没有找到太多关于其实际机制或背后直觉的内容。
问题的关键在于:类 GPT 模型的生成依赖于提示中每个标记(token)之间的关系。仅缓存提示的一部分又怎么会有意义呢?
令人惊讶的是,它确实有意义。让我们深入了解一下!
提示缓存最近已成为一项重要的进步,用于减少计算开销、延迟和成本,特别是对于那些频繁重复使用提示片段的应用而言。
需要澄清的是,这些情况通常是你有一个很长的、静态的预提示(上下文),然后不断向其中添加新的用户问题。每次调用 API 模型时,它都需要完全重新处理整个提示。
谷歌率先推出了 Gemini 模型的上下文缓存(Context Caching),而Anthropic和OpenAI最近也集成了各自的提示缓存功能,声称能大幅降低长提示的成本和延迟。
什么是提示缓存?
提示缓存是一种技术,它存储提示的一部分(例如系统消息、文档或模板文本),以便高效地重复使用。这避免了重复处理相同的提示结构,提高了效率。
实现提示缓存有多种方式,因此不同提供商的技术可能有所不同,但我们将尝试从两种流行方法中抽象出其核心概念
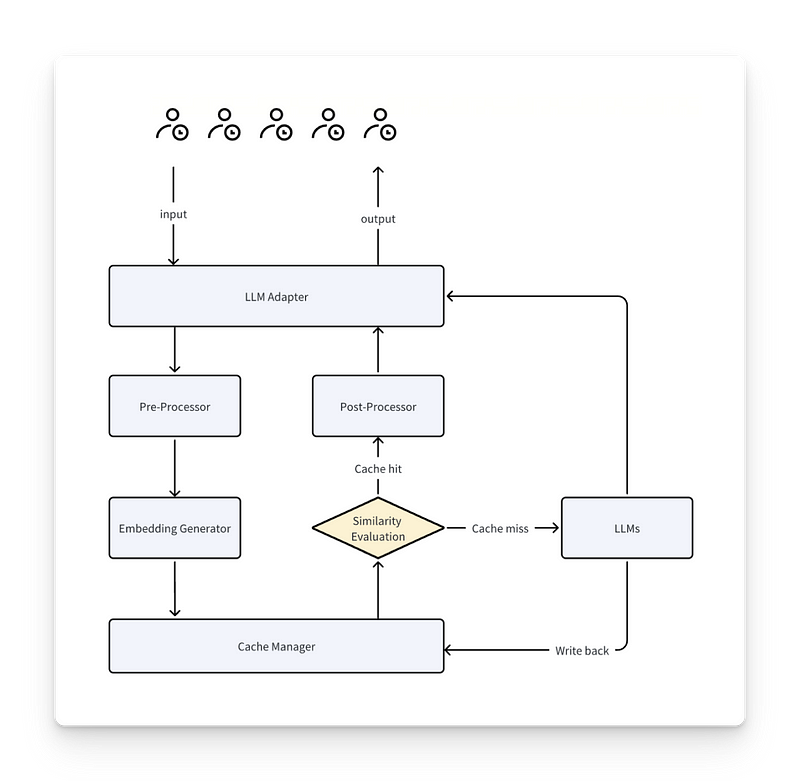
整个过程如下
- 当提示输入时,它会经历标记化、向量化和完整的模型推理过程(对于 LLMs 来说通常是注意力模型)。
- 系统将相关数据(标记及其嵌入)存储在模型外部的缓存层中。标记的数值向量表示存储在内存中。
- 在下次调用时,系统会检查新提示的一部分是否已存储在缓存中(例如,基于嵌入相似性)。
- 如果命中缓存,则检索缓存部分,跳过标记化和完整的模型推理。
那么……具体缓存了什么?
在最基本的形态下,可以根据具体方法应用不同级别的缓存,从简单到复杂不等。这可能包括存储标记、标记嵌入,甚至内部状态,以避免重复处理。
- 标记(Tokens):下一级别涉及缓存提示的标记化表示,避免重复输入时需要重新进行标记化。
- 标记编码(Token Encodings):缓存这些内容使模型能够跳过对先前输入进行重新编码,而仅处理提示的新部分。
- 内部状态(Internal States):在最复杂的级别,缓存内部状态(如键值对,见下文)存储了标记之间的关系,因此模型只需计算新的关系。
缓存键值状态
在 Transformer 模型中,标记以对的形式处理:键(Keys)和值(Values)。
- 键(Keys)帮助模型决定每个标记应该给予其他标记多少重要性或“注意力”。
- 值(Values)代表标记在上下文中贡献的实际内容或意义。
例如,在句子“Harry Potter is a wizard, and his friend is Ron,”中,“Harry”的键是一个向量,其中包含与句子中其他每个词的关系
["Harry", "Potter"], ["Harry"", "a"], ["Harry", "wizard"], 等等...
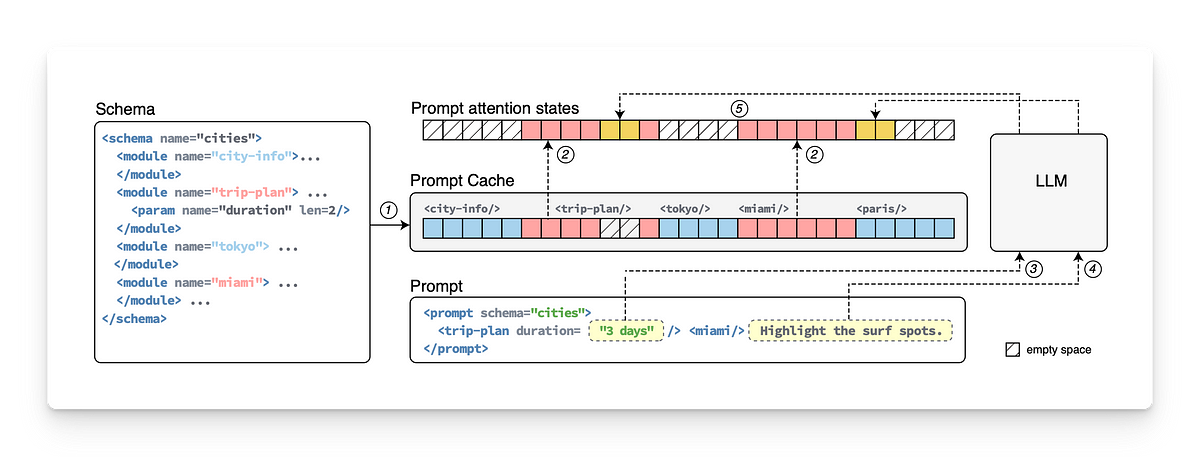
KV 提示缓存的工作原理
- 预计算并缓存 KV 状态:模型计算并存储常用提示的 KV 对,从而跳过重新计算,并从缓存中检索这些对以提高效率。
- 合并缓存和新上下文:在新的提示中,模型检索先前使用的句子的缓存 KV 对,同时计算任何新句子的新 KV 对。
- 跨句子 KV 计算:模型计算新的 KV 对,将一个句子中缓存的标记与另一个句子中的新标记联系起来,从而全面理解它们之间的关系。
总结
缓存提示中标记之间的所有关系都已计算完毕。只需计算 NEW-OLD 或 NEW-NEW 标记之间的新关系。
这是 RAG 的终结吗?
随着模型上下文大小的增加,提示缓存通过避免重复处理将产生巨大影响。因此,有些人可能会倾向于只使用巨大的提示并完全跳过检索过程。
但问题是:随着上下文变大,模型会失去焦点。这不是因为模型表现不好,而是因为在大量数据中找到答案是一个主观任务,取决于具体的使用场景需求。
能够存储和管理大量向量的系统仍然至关重要,而且 RAG 通过提供一些关键功能超越了提示缓存:控制。
使用 RAG,你可以过滤并仅从数据中检索最相关的块,而不是依赖模型处理所有内容。这种模块化、分离的方法确保了更少的噪音,提供了比全上下文输入更高的透明度和精确度。
最后,随着更大上下文模型的出现,可能需要更好的提示向量存储方案,而不仅仅是简单的缓存。这是否意味着我们又回到了……向量数据库?
在 Langflow,我们正在构建从 RAG 原型到生产的最快路径。它是开源的,并提供免费云服务!请访问 https://github.com/langflow-ai/langflow 查看 ✨