迁移学习、预训练还是微调?
了解机器学习概念在生成式AI时代的演变
回到机器学习的早期,当模型训练只是在几块GPU上进行的周末项目时,预训练、微调和迁移学习的概念感觉简单明了。你会抓取一个预训练模型,在其顶部添加一个分类器头部,针对你的任务进行微调,然后就大功告成了。
如果你曾经历过可以在消费级GPU上微调GPT-2或BERT等模型的时代,那么今天的术语可能会让人感到……困惑。由于大型语言模型提供商的需求,曾经定义明确的概念现在描述的是截然不同的工作流程。
机器学习不仅在规模上发生了演变;我们沟通的方式也适应了这些新的工作流程。理解这些概念是如何演变的——并保持沟通清晰——可能是为一些技术讨论带来一定清晰度的关键!
总结
神经网络时代(ChatGPT之前)
- 预训练:在通用数据上训练大型模型(基础)。
- 微调:调整预训练模型以适应特定任务。
- 迁移学习:利用一项任务/模型的知识来完成另一项任务。
生成式AI时代(2024/25)
- 预训练:由提供商完成(OpenAI、Anthropic)——模型进行广泛学习。
- 微调:你根据自己的应用定制模型(例如,OpenAI的微调API)。
- 迁移学习:在API中默认发生——LLMs针对你的查询/任务调整其预训练知识。
预训练:从小规模到工业级
在早期,预训练意味着教授模型基础知识。对于图像,可能涉及检测边缘和纹理;对于文本,学习语法和句法。这个过程雄心勃勃,但只要有足够的耐心和几块GPU,就可以实现。一个实验室——甚至一个资源充足的个人——都可以做到。
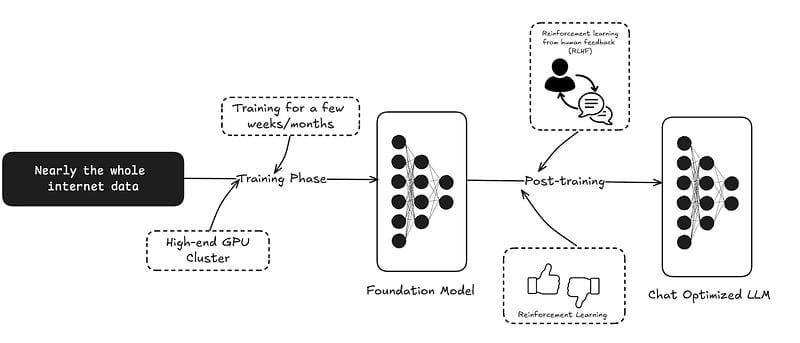
如今,在生成式AI时代,预训练通常涉及数万亿个token、海量数据集以及跨越数千块GPU的基础设施。像GPT-4和Claude这样的模型不仅仅是预训练的;它们是基础模型,能够跨无数领域进行通用推理。
- 示例:训练GPT-4涉及从各种在线内容中获取的庞大数据集,使其能够泛化到回答问题、总结和编程等任务。
这一转变意味着预训练对于大多数人来说已经遥不可及。它不再是你工作流程中的一步——它是现代生成式AI生态系统的基础,由少数拥有扩展资源的大型组织负责。
今天的大多数聊天模型在预训练之后会经历一个后训练步骤,其中包括人类反馈强化学习(RLHF)。这个过程将一个语言模型——一个纯粹的下一个token预测器——转化为一个具有聊天式响应、对人友好的模型。
这被称为指令微调(instruct-tune),它是微调的一部分。但在大多数LLM语境中,谈论微调通常指的是领域特定的微调,我们将在下面介绍。
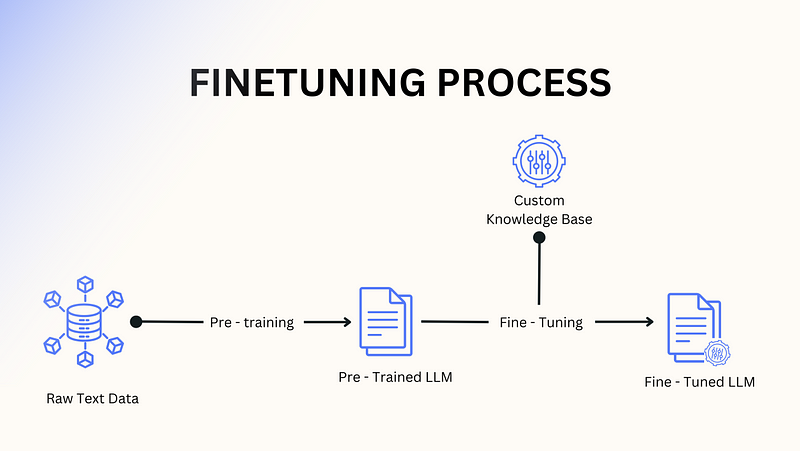
微调:微妙的演变
在神经网络时代,微调是直截了当的。你会拿一个预训练模型,为其特定任务附加一个新的层(头部),然后在你的数据集上对其进行训练。基础模型基本保持不变,而任务特定的头部则学习分类、预测或生成输出。
在生成式AI时代,微调现在意味着直接调整模型的权重,通常跨越所有层,而无需添加任何新的东西。它关乎教导模型针对你的用例进行专门化——使其行为与你的目标对齐——同时保留其通用能力。
- 示例:OpenAI的微调API允许公司根据特定风格生成技术文档或回答小众领域问题等任务来定制GPT-4。
微调已经从结构性改变转向微妙的行为优化,使企业能够根据其特定需求调整强大的模型。
迁移学习:默认模式
在神经网络时代,迁移学习是实用工作流程的基石。你会冻结模型的早期层——存储通用特征的地方——并微调任务特定的部分。这是一种无需从头开始即可重用知识的有效方式。
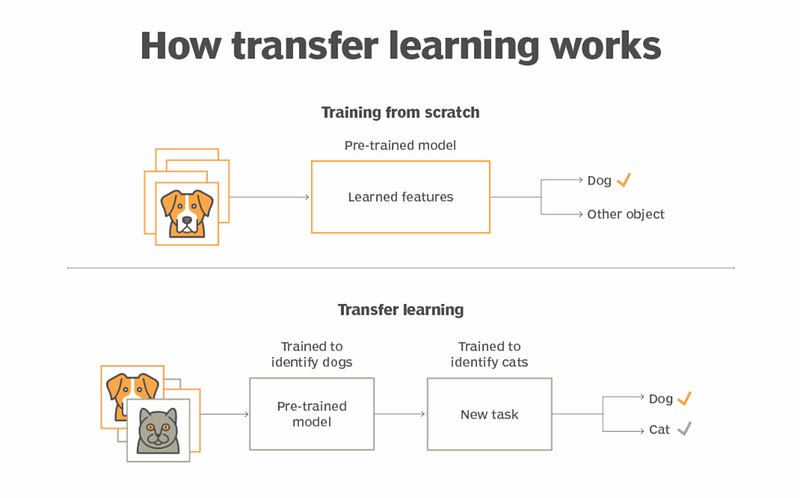
在生成式AI时代,迁移学习是内置到系统中的。这些模型本质上是通用的,将它们适应新任务通常只需要一个精心设计的提示。微调甚至可能不是必需的。
- 示例:与其微调GPT-4来起草法律合同,你可以用几个示例提示来引导它,动态地利用其预训练知识。
迁移学习现在感觉是隐形的,通过交互而非显式重新训练无缝发生。
从神经网络到生成式AI时代的转变从根本上改变了这些核心概念的规模、工作流程和相关沟通。预训练现在是一个工业规模的操作,微调侧重于微调调整而非结构性改变,而迁移学习则无缝集成到现代生成式AI工作流程中。
对于那些从小规模时代开始的人来说,这些转变可能看起来像是彻底的改变。但其原则保持一致。理解这些概念在生成式AI范式中是如何适应的,有助于弥合传统工作流程与现代AI巨大潜力之间的差距。
在Langflow,我们正在构建通往AI开发的最快路径——从原型到生产。它是开源的,并提供免费云服务!请访问 www.langflow.org 查看 ✨